단층 퍼셉트론(SLP, Single Layer Perceptron)의 정의
- 단층 퍼셉트론은 일련의 퍼셉트론을 한 줄로 배치하고, 입력 벡터 하나로부터 출력 벡터 하나를 얻을 수 있는 구조를 가지고 있다.
- 입력 벡터만을 공유할 뿐이고, 각자의 파라미터에 따라 독립적으로 수행된다.
- 비록 간단한 구조지만, 여러 고급 신경망 구조의 기본 요소라고 할 수 있다.
퍼셉트론 신경망 구조
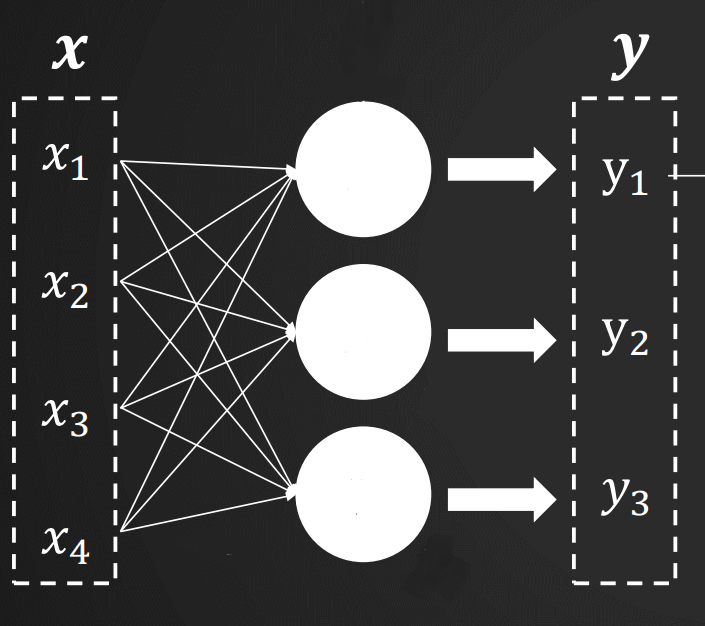
- x1, x2, ... 를 입력계층이라고 한다.
- y1, y2, ... 를 출력계층이라고 한다.
- 단층 퍼셉트론은 단순히 입력계층과 출력계층으로 구성되어 있다.
- 각 '퍼셉트론'이 입력계층에서 얻은 입력값에 가중치를 곱해 수식을 계산하고 값을 출력한다.
- 파라미터 : 학습 과정 중 변경되어 가면서 퍼셉트론의 동작 특성을 결정하는 값 (가중치, 편향)
- 단층 퍼셉트론에서는 퍼셉트론 끼리 영향을 주고 받을 수 없기 때문에 높은 수준의 문제는 해결할 수 없음
텐서 연산과 미니배치의 활용
- 텐서(tensor) : 다차원 숫자배열. 0차원 스칼라, 1차원 벡터, 2차원 행렬, 3차원 이상의 배열 모두가 텐서라고 할 수 있다.
- 같은 문제일지라도 반복문보다 텐서를 통해 처리하는 것이 프로그램도 간단하고 처리속도도 빠르다. (머신러닝에 주로 쓰이는 파이썬 인터프리터가 반복문보다 텐서연산을 더 효율적으로 처리하기 때문이다. 이러한 차이는 GPU같이 환경이 제대로 갖춰진 곳이라면 더 커진다.)
- 배치(batch) : 전체 학습데이터를 한번에 일괄처리하는 것
- 미니배치(minibatch) : 전체 학습데이터를 잘라서 한번에 일괄처리하는 것으로, 딥러닝에서 신경망 여러 데이터 한번에 처리하는 것을 뜻한다.
- 선형 vs 비선형 : 입력 성분의 일차식으로 표현이 가능한 과정을 선형연산이라고 하고, 일차식으로는 나타낼 수 없는 연산을 비선형 연산이라고 한다.
- 에폭(epoch) : 학습데이터 전체에 대한 한 차례 처리
- 하이퍼 파라미터 : 에폭 수나 미니배치 크기는 학습과정에서 변경되지 않지만 신경망 구조나 학습 결과에 영향을 미친다. 이렇게 변경되지 않으면서 결과에 영향을 미치는 요인을 하이퍼파라미터라고 한다.
신경망의 세가지 기본 출력 유형과 회귀분석
- 회귀분석 : 연속형 변수사이의 모델을 구한뒤 적합도를 측정하는 분석 방법
- 이진분석 : 둘중하나를 선택하는 것 (추후 자세히)
- 선택분석 : 몇가지중 선택하는 것 (추후 자세히)
- cf. 구글 집중단기과정 (머신러닝 단기집중과정) : https://developers.google.com/machine-learning/crash-course?hl=ko
평균제곱오차 손실함수
- 평균제곱오차(MSE, mean squared error) : 추정값과 정답 사이의 차이인 오차를 제곱한 뒤 평균을 구한 값
- 손실함수(loss function) : 항상 0 이상이며 추정이 정확해질 수록 값이 작아지는 성질이 있다. 또한 미분이 가능해야 한다. 이를 최소화하는 것이 딥러닝의 목표이다. 입력값, 가중치 등에 따라 해당 결과값이 달라진다. 평균제곱오차도 손실함수 중 하나이다.
경사하강법과 역전파
-
경사하강법 : 기울기에 따라 함숫값이 낮아지는 방향으로 이동하는 기법이다. 순전파와 역전파를 반복하여 진행하여 신경망 구조를 원하는 방향으로 바꿔나간다.
-
순전파 : 입력 데이터에 대해 신경망 구조를 따라가면서 현재의 파라미터값들을 이용해 손실함숫값을 계산하는 과정
-
역전파 : 순전파의 계산과정을 역순으로 거슬러 가면서 손실 함숫값에 직간접적으로 영향을 미친 모든 성분에 대해 손실 기울기를 계산하는 과정
-
손실기울기 : 특정 파라미터에 관한 편미분값. 손실기울기에 학습률을 곱해 이를 활용해 '학습'을 진행한다.
-
학습률 : 하이퍼 파라미터로서, 학습에 활용되는 임의의 양수값이다. 임의의 양수값을 사용할 수 있지만 값이 커지면 목표 근처에서 정확하게 최저점을 찾는 능력이 무뎌질 수 있고, 값이 작아지면 최저점에 접근하는 시간이 더 오래걸릴 수 있다.
-
Adam : 학습률이 작으면 값도달까지의 시간이 오래걸리고, 학습률이 크면 보폭이 너무 커서 값에 도달할 수 없을 수 있다. 이러한 고정된 학습률의 단점을 보완하기 위하여 학습 초반에는 큰 학습률을 사용하고, 바닥점에 가까워 질 수 록 학습률을 줄이는 기법.
원-핫 벡터 표현
- 각 아이템을 단순히 숫자로만 표현하면 문제가 발생할 수 있다. (사과 - 1, 오렌지 - 2, 멜론 - 3)
- 머신러닝에서는 데이터를 표현할 때 벡터를 사용하기 때문이다.
- 따라서 원-핫 벡터를 사용한다.
- 각 단어에 고유한 인덱스 부여하고, 표현하고 싶은 단어의 인덱스 위치에 1을 부여한다. 그리고 다른 단어의 인덱스 위치에는 0을 부여한다.
- ex. 사과 - [1, 0, 0] / 오렌지 - [0, 1, 0] / 멜론 - [0, 0, 1]
'🛠 기타 > Data & AI' 카테고리의 다른 글
| Pandas 데이터프레임 활용 통계값 계산 (0) | 2020.07.14 |
|---|---|
| [파이썬] Pandas 데이터프레임 전치행렬 만들기 (0) | 2020.07.13 |
| [파이썬] Pandas 기초 - DataFrame 결합 (0) | 2020.07.09 |
| [파이썬] Pandas 기초 - DataFrame 슬라이싱 (0) | 2020.07.09 |
| [파이썬] Pandas 기초 - DataFrame 생성 (컬럼 수정,추가, 삭제) (0) | 2020.07.09 |