Seq2Seq
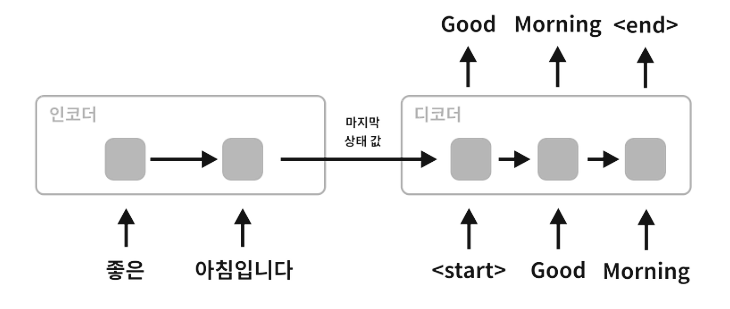

- 문장을 입력받아 문장을 출력한다. 인코더와 디코더로 이루어져 있다.
- 인코더에서는 전체 입력정보를 순환적으로 처리하여(RNN, LSTM 사용) 히든 스테이트와 셀 스테이트, 즉 상태값으로 저장한다.
- 디코더에서는 해당 정보를 기반으로 OUTPUT을 하나씩 출력한다. 처음엔 인코더로부터 받은 상태값들을 기반으로 <START>을 디코더 첫입력값으로 입력한다. (물론 <START>가 아니어도 상관없다. 시작을 알리기에 보편적으로 사용할 수 있는, 일반적이지 않아 다른 문자열과 혼동될 문제가 없는 문자열이면 충분하다.) 그리고 디코더에서도 상태값들(히든 스테이트, 셀 스테이트)를 출력하게 된다.
- <START>와 인코더 상태값을 입력했을 때 출력된 출력값을 다시 입력으로 사용한다. 그리고 이전 상태의 상태값들을 기반으로 다시 신경망을 통과한다.
- 그러다 <END> 결과가 나오면 순환을 종료한다.
- <START>와 <END>는 모델 학습 수행시 결정해주는 것이다. 다른 구별 문자를 넣어줘도 크게 문제될 것은 없다.
- 실질적으로는 두번 째 그림처럼 임베딩된 데이터가 들어가고 소프트맥스 함수로 단어별 확률값이 출력될 것이다.
챗봇 데이터 활용 예제 : 데이터 전처리 및 준비
import numpy as np
import re
import pandas as pd
import csv
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
chatbot = pd.read_csv("../data/ChatbotData.csv")
chatbot['Q'] = chatbot['Q'].str.replace("[^\w]", " ")
chatbot['A'] = chatbot['A'].str.replace("[^\w]", " ")- 데이터를 불러오고 Q, A 데이터 모두에서 숫자 혹은 문자가 아닌 문자들을 제거한다.
encoder_input, decoder_input, decoder_output = [], [], []
for stc in chatbot['Q']:
encoder_input.append(stc.split())
for stc in chatbot['A']:
decoder_input.append(("<start> "+stc).split())
for stc in chatbot['A']:
decoder_output.append((stc+" <end>").split())- 데이터를 불러와 단어별로 나누고 저장한다.
- 디코더 input과 output은 각각 앞뒤에 '<start> '와 ' <end>'를 붙여준다. (원활한 split을 위해 띄어쓰기도 함께 추가)
tokenizer_q = Tokenizer()
tokenizer_q.fit_on_texts(encoder_input)
encoder_input = tokenizer_q.texts_to_sequences(encoder_input)
tokenizer_a = Tokenizer()
tokenizer_a.fit_on_texts(decoder_input)
tokenizer_a.fit_on_texts(decoder_output)
decoder_input = tokenizer_a.texts_to_sequences(decoder_input)
decoder_output = tokenizer_a.texts_to_sequences(decoder_output)- input과 output 각각 tokenizer 객체를 생성해서 fit시키고 토큰화(인덱싱)한다.
encoder_input = pad_sequences(encoder_input, padding="post")
decoder_input = pad_sequences(decoder_input, padding="post")
decoder_output = pad_sequences(decoder_output, padding="post")- 각 문장의 길이를 맞추기 위해 패딩을 추가한다. mex_len을 따로 명시하지 않으면 자동으로 인풋값 중 최대길이에 맞춰진다.
- padding = "post" 옵션은 0이 뒤쪽에 붙도록 해준다. (0이 앞에 붙으면 필요없는 정보를 먼저 확인하게 되므로)
a_to_index = tokenizer_a.word_index
index_to_a = tokenizer_a.index_word- 아웃풋(대답)의 단어들에 대한 인덱싱을 불러온다.
- a_to_index는 단어를 인덱스화하고, index_to_a는 인덱스를 단어화한다.
test_size = 2500
encoder_input_train = encoder_input[:-test_size]
decoder_input_train = decoder_input[:-test_size]
decoder_output_train = decoder_output[:-test_size]
encoder_input_test = encoder_input[-test_size:]
decoder_input_test = decoder_input[-test_size:]
decoder_output_test = decoder_output[-test_size:]- 데이터의 크기를 보고 적당한 크기로 나눠 학습 데이터셋과 테스트 데이터셋은 나눠 제작한다.
챗봇 데이터 활용 예제 : 모델 초기화 및 학습
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Masking
from tensorflow.keras.models import Model
encoder_inputs = Input(shape=(15,))
encoder_embed = Embedding(len(tokenizer_q.word_index)+1, 50)(encoder_inputs)
encoder_mask = Masking(mask_value=0)(encoder_embed)
encoder_outputs, h_state, c_state = LSTM(50, return_state=True)(encoder_mask)- 인코더 신경망 설계
- Input : 15(패딩 포함 질문 문장길이)를 입력으로 받는다.
- Embedding: len(tokenizer_q.word_index)+1개(패딩값포함)의 인덱스로 되어있는 정보를 50차원으로 임베딩한다.
- Masking : 패딩값에 해당하는 0 정보를 거르기 위해 사용된다. mask_value에 해당하는 값을 제거한다.
- LSTM : 단어를 순환신경망에 넣어 encoder_outputs, h_state, c_state을 리턴하도록 한다.
decoder_inputs = Input(shape=(22,))
decoder_embed = Embedding(len(tokenizer_a.word_index)+1, 50)(decoder_inputs)
decoder_mask = Masking(mask_value=0)(decoder_embed)
decoder_lstm = LSTM(50, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_mask, initial_state=[h_state, c_state])
decoder_dense = Dense(len(tokenizer_a.word_index)+1, activation='softmax')
decoder_softmax_outputs = decoder_dense(decoder_outputs)- 디코더 신경망 설계
- Input : 22(패딩 포함 대답 문장길이)를 입력으로 받는다.
- Embedding: len(tokenizer_a.word_index)+1개(패딩값포함)의 인덱스로 되어있는 정보를 50차원으로 임베딩한다.
- Masking : 패딩값에 해당하는 0 정보를 거르기 위해 사용된다. mask_value에 해당하는 값을 제거한다.
- LSTM : 단어를 순환신경망에 넣어 decoder_outputs를 리턴하도록 한다. 초기 상태값으로 주어진 h_state, c_state를 활용한다.
- Dense : 단어별 인덱스 확률을 뽑아낸다. (softmax 사용)
model = Model([encoder_inputs, decoder_inputs], decoder_softmax_outputs)
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['acc'])
model.fit(x = [encoder_input_train, decoder_input_train], y = decoder_output_train, validation_data = ([encoder_input_test, decoder_input_test], decoder_output_test), batch_size = 128, epochs = 100)- 함수형 케라스를 통해 최종적으로 모델을 제작한다. inputs로 [encoder_inputs, decoder_inputs], outputs로 decoder_softmax_outputs를 준다.
- 이렇게 생성된 모델을 컴파일 및 학습 데이터에 대해 학습시켜 완성한다.
- 이렇게 완성된 신경망들은 '학습'에 사용된다. 각 레이어가 이러한 과정을 통해 학습되기 때문에 추후 실질적 예측에서는 이 신경망의 일부를 가져와 활용한다.
챗봇 데이터 활용 예제 : 예측
encoder_model = Model(encoder_inputs, [h_state, c_state])- 인코딩 결과로 발생할 상태값도 가져오기 위해 그를 반환할 모델 (encoder_model)
encoder_h_state = Input(shape=(50,))
encoder_c_state = Input(shape=(50,))
pd_decoder_outputs, pd_h_state, pd_c_state = decoder_lstm(decoder_mask, initial_state=[encoder_h_state, encoder_c_state])
pd_decoder_softmax_outputs = decoder_dense(pd_decoder_outputs)
decoder_model = Model([decoder_inputs, encoder_h_state, encoder_c_state], [pd_decoder_softmax_outputs, pd_h_state, pd_c_state])- Input : 디코더 모델을 만들건데, 디코더 모델에 초기값으로 넣을 상태값의 모양을 지정한다. (앞서 확인한 결과 상태값은 (50,)의 형태도 지정되어 있다. 따라서 shape=(50,))
- decoder_lstm : 그러한 상태값들을 초기값으로 쓰고, 앞서 지정한 decoder_mask함수 케라스를 활용해 새로운 결과값과 상태치를 가져온다.
- decoder_dense : 결과치를 기반으로 소프트맥스 결과를 뽑아내 단어를 찾아낼 수 있도록 한다.
- 이것을 모델화하여 사용한다 (decoder_model)
input_stc = input()
token_stc = input_stc.split()
encode_stc = tokenizer_q.texts_to_sequences([token_stc])
pad_stc = pad_sequences(encode_stc, maxlen=15, padding="post")
states_value = encoder_model.predict(pad_stc)
predicted_seq = np.zeros((1,1))
predicted_seq[0, 0] = a_to_index['<start>']
decoded_stc = []
while True:
output_words, h, c = decoder_model.predict([predicted_seq] + states_value)
predicted_word = index_to_a[np.argmax(output_words[0,0])]
if predicted_word == '<end>':
break
decoded_stc.append(predicted_word)
predicted_seq = np.zeros((1,1))
predicted_seq[0,0] = np.argmax(output_words[0,0])
states_value = [h, c]
print(' '.join(decoded_stc))- 최종 예측을 수행한다.
- 먼저 encoder_model로 input의 최종 상태값을 얻어낸다.
- 그리고 <start>에 해당하는 인덱스를 (1,1)의 numpy 배열에 할당하고 decoding 수행을 시작한다. 초기 상태값은 인코딩 결과로 받은 상태값이다. 이러한 결과로 예측 단어와 새로운 상태값이 도출될 것이다. 또 다시 그를 기반으로 decoding을 수행한다. 이를 반복하다가 <end>가 예측 단어로 확인되면 반복을 멈춘다.
- 결과는 계속 decoded_stc에 추가해준다. 마지막엔 join을 통해 한번에 결과문을 출력해준다.
'🛠 기타 > Data & AI' 카테고리의 다른 글
| [scikit-learn 라이브러리] GradientBoosting (0) | 2020.08.19 |
|---|---|
| Attention 기초 (리뷰 요약하기 예제) (1) | 2020.08.18 |
| 함수형 케라스와 모델 합성(앙상블) (0) | 2020.08.14 |
| 뉴스 헤드라인 기반 카테고리 분류하기 (0) | 2020.08.14 |
| 텐서플로우 허브 (0) | 2020.08.14 |