SVM이란?
- SVM은 분류에 사용되는 지도학습 머신러닝 모델이다.
- SVM은 서포트 벡터(support vectors)를 사용해서 결정 경계(Decision Boundary)를 정의하고, 분류되지 않은 점을 해당 결정 경계와 비교해서 분류하게 된다.
- 기존의 퍼셉트론은 가장 단순하고 빠른 분류 모형이지만 결정경계가 유일하게 존재하지 않는다.
- 서포트 벡터 머신(SVM)은 퍼셉트론 기반의 모형에 가장 안정적인 결정 경계를 찾기 위해 제한 조건을 추가한 모형이라고 볼 수 있다.
- 서포트 벡터 : 클래스 사이 경계에 가깝게 위치한 데이터 포인트 (결정 경계와 이들 사이의 거리가 SVC 모델의 dual_coef_에 저장된다.)
커널 기법
- 데이터셋에 비선형 특성을 추가하면 선형 모델을 더 강력하게 만들 수 있음
- 하지만, 어떤 특성을 추가해야 할지 알 수 없고, 특성을 많이 추가하면 연산 비용이 커진다.
- 커널 기법 : 새로운 특성을 만들지 않고 고차원 분류기를 학습시킬 수 있도록 한다. 주어진 데이터를 고차원의 특징 공간ㅇ으로 사상해, 원래의 차원에선 포이지 않던 선형(초평면)이 데이터를 분류할 수 있도록 한다.
- 고차원 공간 맵핑 방법 : 가우시안 커널, RBF (Radial Basis Function) 커널
SVM의 튜닝
- gamma변수와 C변수를 조절하여 튜닝이 이루어진다.
- gamma 매개변수는 하나의 훈련 샘플이 미치는 영향의 범위를 결정한다.
- C 매개변수는 각 포인트의 중요도(정확히는 dualcoef 값)를 제한하는 매개변수로, 해당값이 커질수록 결정경계가 데이터에 정확하게 맞춰진다.
- 아래 그림은 같은 데이터에 대해 gamma 변수와 C 변수를 조절한 결과이다.
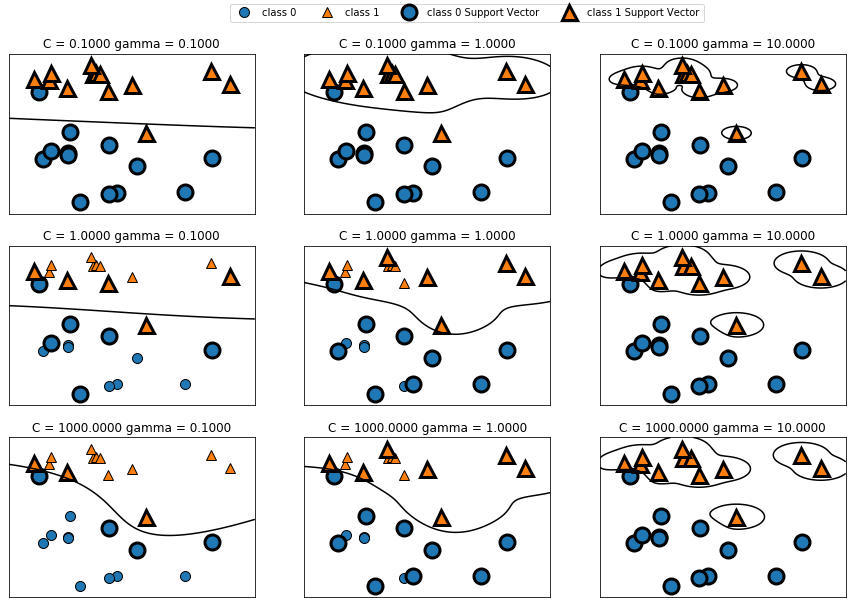
사용예제
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
# 데이터 로드
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,
cancer.target,
random_state=0)
# 모델 학습
model = SVC(gamma=0.01).fit(X_train, y_train)
# 평가
print("훈련 세트 정확도: {:.2f}".format(model.score(X_train, y_train)))
print("테스트 세트 정확도: {:.2f}".format(model.score(X_test, y_test)))==결과==
훈련 세트 정확도: 1.00
테스트 세트 정확도: 0.64- 훈련 세트에는 완벽한 점수를 냈지만 테스트 세트에는 낮은 정확도를 보인다. (=> 과적합)
- SVM은 매개변수 설정과 데이터 스케일에 매우 민감하다.
- 특히 입력 특성들의 범위가 비슷해야 하므로 각 특성의 최솟값과 최댓값을 로그 스케일로 변환하는 것이 좋다.
from sklearn.preprocessing import MinMaxScaler
# 훈련데이터에 대해 스케일링 적용을 위한 조사
scaler = MinMaxScaler()
scaler.fit(X_train)
# 훈련데이터에 대해 스케일링 적용
X_train_scaled = scaler.transform(X_train)
# 테스트데이터에 대해 스케일링 적용
X_test_scaled = scaler.transform(X_test)- MinMaxScaler를 통해 각 특성들에 대한 스케일링을 진행해준다.
# gamma 파라미저 조정
model = SVC(gamma=0.01).fit(X_train_scaled, y_train)
# 평가
print("훈련 세트 정확도: {:.3f}".format(model.score(X_train_scaled, y_train)))
print("테스트 세트 정확도: {:.3f}".format(model.score(X_test_scaled, y_test)))==결과==
훈련 세트 정확도: 0.908
테스트 세트 정확도: 0.937- 훈련 세트에서의 정확도는 줄었지만 테스트 세트 정확도가 상승해 과적합에서 멀어졌음을 알 수 있다.
- 여기서 C와 gamma값을 조절하다보면 더 좋은 모델을 만들 수도 있다.
'🛠 기타 > Data & AI' 카테고리의 다른 글
| Pandas 데이터프레임 출력양 조절 (0) | 2020.08.24 |
|---|---|
| [scikit-learn 라이브러리] 교차 검증 (1) | 2020.08.23 |
| 오토 인코더 기초개념 (0) | 2020.08.23 |
| 기초 추천시스템 - 사용자 기반 협업 필터링 (2) | 2020.08.23 |
| 기초 추천시스템 - 컨텐츠기반 필터링 (2) | 2020.08.21 |