반응형
- 계산값을 기반으로 계산값이 0보다 작으면 -1, 0보다 크면 1로 분류한다.
- 이진 선형 분류기는 선, 평면, 초평면을 이용해 2개의 클래스를 구분하는 분류기이다.
SGDClassifier
SGDClassifier(alpha, average, class_weight, epsilon, eta0, fit_intercept, l1_ratio, learning_rat,
loss, max_iter, n_iter, n_jobs, penalty, power_t, random_state, shuffle, tol, verbose, warm_start)- 확률적 경사하강법(SGD, Stochastic Gradient Descent)을 이용하여 선형모델을 구현
- lossstr : 손실함수 (default='hinge')
- penalty : {'l2', 'l1', 'elasticnet'}, default='l2'
- alpha : 값이 클수록 강력한 정규화(규제) 설정 (default=0.0001)
- l1_ratio : L1 규제의 비율(Elastic-Net 믹싱 파라미터 경우에만 사용) (default=0.15)
- fit_intercept : 모형에 상수항 (절편)이 있는가 없는가를 결정하는 인수 (default=True)
- max_iter : 계산에 사용할 작업 수 (default=1000)
- tol : 정밀도
- shuffle : 에포크 후에 트레이닝 데이터를 섞는 유무 (default=True)
- epsilon : 손실 함수에서의 엡실론, 엡실론이 작은 경우, 현재 예측과 올바른 레이블 간의 차이가 임계 값보다 작으면 무시 (default=0.1)
- n_jobs : 병렬 처리 할 때 사용되는 CPU 코어 수
- random_state : 난수 seed 설정
- learning_rate : 학습속도 (default='optimal')
- eta0 : 초기 학습속도 (default=0.0)
- power_t : 역 스케일링 학습률 (default=0.5)
- early_stopping : 유효성 검사 점수가 향상되지 않을 때 조기 중지여부 (default=False)
- validation_fraction : 조기 중지를위한 검증 세트로 설정할 교육 데이터의 비율 (default=0.1)
- n_iter_no_change : 조기중지 전 반복횟수 (default=5)
- class_weight : 클래스와 관련된 가중치 {class_label: weight} or “balanced”, default=None
- warm_start : 초기화 유무 (default=False)
- average : True로 설정하면 모든 업데이트에 대한 평균 SGD 가중치를 계산하고 결과를 coef_속성에 저장 (default=False)
데이터 로드 및 전처리
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.feature_names)
print(iris.target_names)
X, y = iris.data, iris.target['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
['setosa' 'versicolor' 'virginica']- iris 데이터를 불러오고 독립 데이터들인 data는 X에, 종속 데이터들인 target은 y에 넣어준다.
- iris 데이터의 독립 데이터의 칼럼에는 'sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'가 존재하고 종속 데이터엔 'setosa' 'versicolor' 'virginica' 중 하나인 꽃 종류가 존재한다.
- 이진 분류기 이므로 'setosa'와 '그 외 나머지'로 분류를 진행할 것이다.
X2 = X[:, :2] # 꽂받침의 길이, 넓이
y2 = y.copy()
y2[ y2 == 2 ] = 1- 분류에는 꽃받침의 길이와 넓이인 Sepal length, Sepal width만을 활용한다. 따라서 슬라이싱을 진행에 이를 X2에 넣어주었다.
- versicolor와 virginica는 '그 외 나머지'로 통합되어 분류될 것이기 때문에 이에 대한 분류 결과를 1로 통일해준다. (기존 데이터는 0,1,2로 'setosa' 'versicolor' 'virginica'를 분류하였다.)
from sklearn.model_selection import train_test_split
# test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25)
X_train, X_test, y_train, y_test = train_test_split(X2, y2, test_size=0.5, random_state=3)- 그렇게 만들어진 X2와 y2를 train_test_split 함수에 넣어 학습 데이터와 테스트 데이터로 분류한다.
모델 초기화 및 학습
# 모델학습
from sklearn.linear_model import SGDClassifier
model = SGDClassifier(max_iter=10000)
model.fit(X_train, y_train)- SGDClassifier 모델을 만들고 fit를 통해 학습을 진행한다.
# 결정 경계선
import numpy as np
a = model.coef_[0,0]
b = model.coef_[0,1]
c = model.intercept_
xx = np.linspace(4, 8, 100)
yy = (-a/b) * xx - (c/b)
plt.plot(xx, yy)
plt.scatter( X_train[:, 0][y_train==0], X_train[:, 1][y_train==0], marker='o')
plt.scatter( X_train[:, 0][y_train==1], X_train[:, 1][y_train==1], marker='+')
binary_names = ['decision boundary', 'setosa', 'non-setosa']
plt.legend(binary_names, loc=(0, 1.05))
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")- coef_ (가중치)와 intercept_(편향)으로부터 값을 얻어 정리한다.
- 우리가 얻어낸 식은 $output = ax_1 + bx_2 + c$ 이지만, 현재 우리가 그릴 그래프는 x축이 x1이고 y축이 x2이므로 이에 맞춰서 식을 설정한다.
- $[x_2 = -{{a}\over{b}} x_1 - {{c}\over{b}}]$ <=> $[yy = -{{a}\over{b}} xx - {{c}\over{b}}]$
- 그리고 기존의 X_train과 y_train을 슬라이싱하여 그래프로 표현한다.
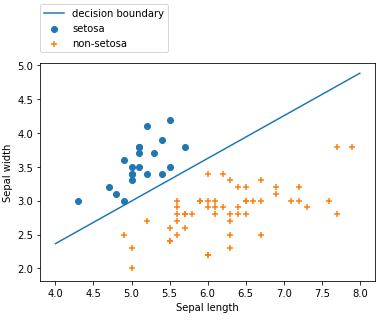
- 제작한 모델이 데이터를 잘 구별해주고 있음을 알 수 있다.
반응형
'🛠 기타 > Data & AI' 카테고리의 다른 글
| 순환신경망 - LSTM 기초 (0) | 2020.07.29 |
|---|---|
| [scikit-learn 라이브러리] LogisticRegression (로지스틱 회귀) (0) | 2020.07.29 |
| [scikit-learn 라이브러리] PolynomialFeatures (다항회귀) (0) | 2020.07.28 |
| 워드 임베딩 - GloVe 기초활용 (0) | 2020.07.28 |
| 단층 퍼셉트론 - 이진판단 구현 확장 (0) | 2020.07.27 |