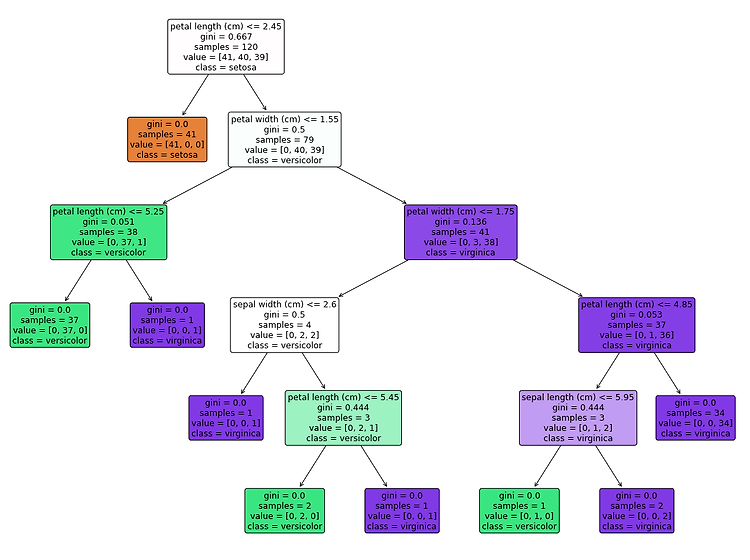
결정트리 분할과 가지치기 과정을 반복하면서 모델을 생성한다. 결정트리에는 분류와 회귀 모두에 사용할 수 있다. 여러개의 모델을 함께 사용하는 앙상블 모델이 존재한다. (RandomForest, GradientBoosting, XGBoost) 각 특성이 개별 처리되기 때문에 데이터 스케일에 영향을 받지 않아 특성의 정규화나 표준화가 필요 없다. 시계열 데이터와 같이 범위 밖의 포인트는 예측 할 수 없다. 과대적합되는 경향이 있다. 이는 본문에 소개할 가지치기 기법을 사용해도 크게 개선되지 않는다. DecisionTreeClassifier() DecisionTreeClassifier(criterion, splitter, max_depth, min_samples_split, min_samples_leaf, m..