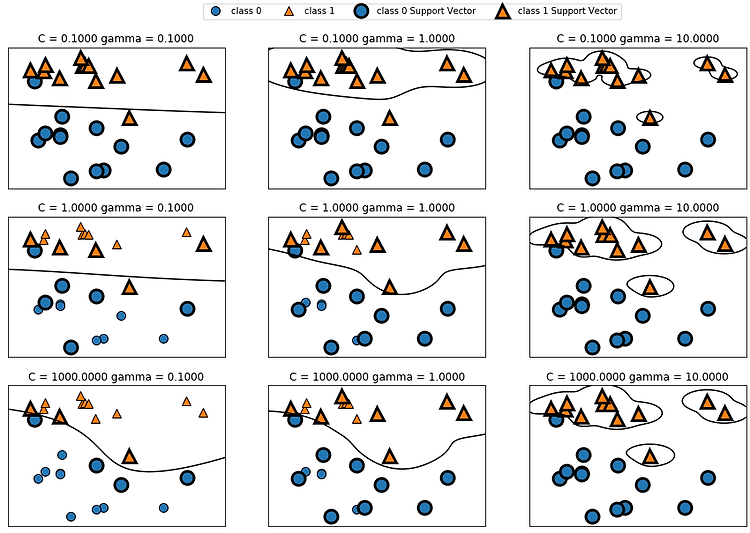
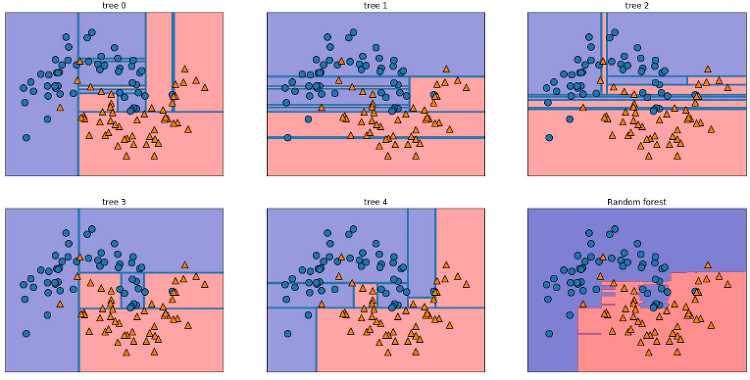
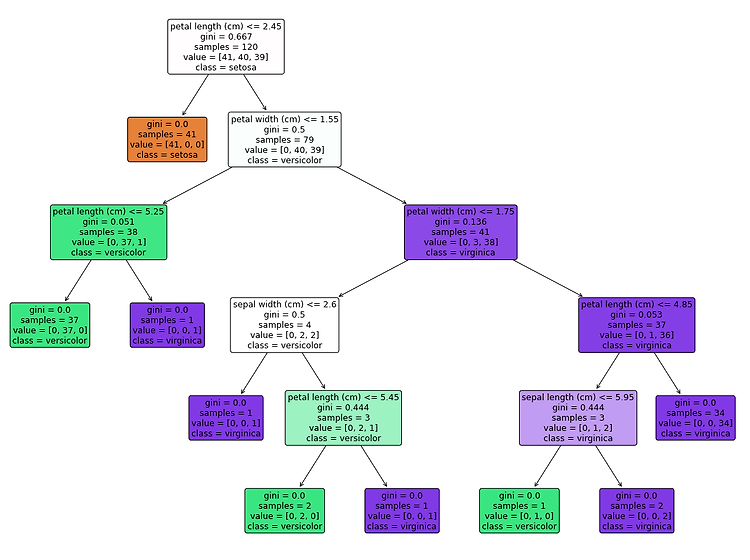
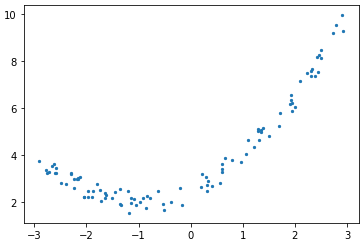
교차 검증 (Cross Validation) 일반화 성능 향상을 위해 훈련 세트와 테스트 세트를 한 번만 나누는 것보다 더 안정적이고 뛰어난 평가 방법이다. 여러개의 세트로 구성된 학습 데이터와 테스트 데이터로 학습과 평가를 수행한다. k-겹 교차검증 : 데이터를 폴드(fold)라는 거의 비슷한 크기의 부분집합 k개로 분리하고 각 부분집합의 정확도를 측정한다. 교차 검증의 점수가 높을수록 데이터셋에 있는 모든 샘플에 대해 모델이 잘 일반화되게 된다. 하지만 연산비용이 늘어나게 된다는 단점이 있다. scikit-learn에서 교차 검증은 model_selection 모듈의 cross_val_score라는 함수로 구현되어 있다. cross_val_score() cross_val_score(estimator,..